
Author: Daniel Cleary
Institution: California Institute of Technology
Date: August 2006
0.0 Abstract
This experiment examined the overall times required to make messaging calls in parallel programs within a distributed computing environment. These messaging calls are defined in the Message Passing Interface (MPI) standards, which is a set of recommendations for designing communication calls for parallel programs. Different libraries based on the MPI standards exist, and this project focused on two commonly used implementations: MPICH and LAM-MPI. Both provide the same essential methods and functions, but their package and algorithm structures differ enough so that the administrative, processing, and messaging times of a program may be improved by selecting one package over the other. With adequate foreknowledge of the strengths and weaknesses of the MPI packages, programmers and administrators can better select a package based on their needs. For both packages, the experiment measured the function run-times in a cluster environment for commonly used, global and point-to-point MPI communication methods. In direct comparison, neither implementation entirely dominated in any category, but both had distinct advantages in programming. The experiments showed that each implementation had significant benefits and areas in which it provided the faster data transfers. With one notable exception, the messaging calls with LAM-MPI had lower function run-times and were noticeably faster (as much as four fold) when using multiple processors.
1.0 Introduction
The "commodity" supercomputers, Beowulf clusters, are a prominent presence in the world of modern high-performance computing and computation. Many of the top five-hundred supercomputers in the world, while not built from commodity hardware, are based on this distributed design paradigm. A distributed supercomputer combines the processing power of many smaller computers, in the form of dedicated compute nodes or even desktop machines, into a single computing machine. Among the super computers using the distributed paradigm is the Earth Simulator, a Japanese supercomputer that surpassed all other supercomputers with a peak theoretical performance of 40 teraflops (40,000 billion floating point operations per second). Many cluster supercomputers use variants of the open-source operating system Linux, and with Linux come a plethora of open-source tools that facilitate inter-node communication within parallel programs. Many open-source, parallel computing communications packages are based on the Message Passing Interface (MPI) standards and are freely available for most modern computer architectures and operating systems. Packages that implement the MPI standards facilitate communication between processes and are thus processor independent; this distinction allows parallel programs using MPI to run in the same manner on many different systems, including single and dual processor machines and heterogeneous clusters. For the commonly used MPI implementations, previous work has measured differences in performance as related to networking capabilities (Ong et al., 2000; Thakur and Gropp, 2003; Benson et al., 2003; Van Voorst and Siedel, 2000). Ong and Farrell (2000) compared three MPI-based implementations (MPICH, LAM-MPI, MVICH) and focused on how network variables affect messaging times. They showed network tuning strongly affected run-times but also found that each package had distinct performance advantages. This experiment followed a similar direction. The goal was to assess the features of two packages, MPICH and LAM-MPI, and to show how the differences in runtimes and implementations could make one package faster or better than the other (Protopopov and Skjellum 2001).
The primary aim of the experiment was to design and test parallel FORTRAN90 code with two MPI implementations on a homogenous, five-node cluster running Pentium-Pro processors. For the 32-bit, Intel x86 based architecture, MPICH and LAM-MPI are two freely available and commonly used MPI based packages (Foster et al., 1997; Squyres and Lumsdaine, 2001; Swann 2001). Both are open-source packages that include a set of libraries based on the MPI standard, scripts for installation and run-time, and pre-compiled programs that facilitate programming with MPI. MPICH is largely developed, maintained, and hosted by Argonne National Laboratories. The package is highly flexible and easy to use: MPICH source code and compiled packages are available for a broad range of architectures and operating systems, including versions for Microsoft Windows based on the NT kernel. MPICH also supports much of the newest version of the MPI standard (MPI-2). The most recent release version of LAM (Local Area Multiprocessor) MPI also supports the MPI-2 standard, which is somewhat better supported and has had more development time. LAM-MPI is available as source code and in compiled packages for different systems; it supports the Apple OS-X based operating systems and offers some compatibility with the Microsoft Windows operating systems.
The programming interface between the two packages differs only slightly, but the underlying algorithms of the two MPI libraries make them very different. This project compared the differences in times for the same message passing calls between MPICH and LAM-MPI and determined if either package performed better than the other. Hardware and software choices for a cluster clearly affect program run times, but factors besides raw computational time can affect the length of time required to conduct a computational experiment (Farrell and Ong, 2003).
2.0 Methods and Materials
The project consisted of three main foci: physically constructing the Beowulf cluster, setting up the software on each node, and programming the four parallel programs. Each part of the project determined some functionality within the system; the combination of the hardware, the software, and the programs determined how well each package responded. By using a homogenous cluster with the exact same operating system, hardware, and software on each node, the project had fewer variables that would affect run-times. Thus any run-time impedances were universal between programs and packages.
2.1 Hardware
The lowest level and first part was the hardware layout. The cluster was built with five nodes, which was the maximum amount of nodes the switch could handle. The computational nodes all received upgrades in memory and downgrades in hardware to achieve homogeneity. The nodes were also identical in terms of the operating system and software. The resulting cluster was homogeneous with respect to hardware and software, with necessary networking, software, and hardware exceptions on the head node.
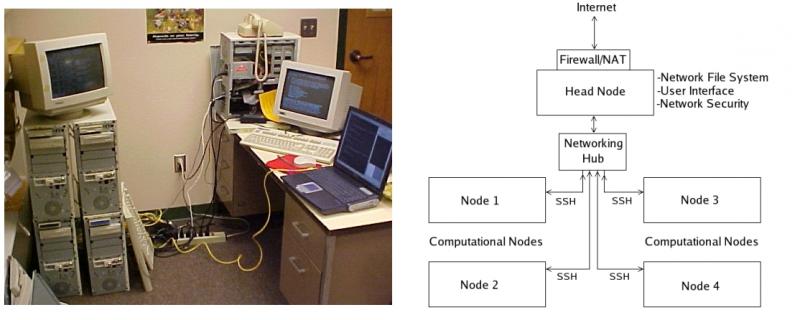
Figure 1: The five-node Beowulf cluster, Jaguar planning diagram and during testing phase. The cluster consisted of four identical, computational nodes and a head node. Each computational node was designed only to run calculations; user access was only available through SSH by submitting parallel calculations. The head node had a modified hardware and software setup to accommodate user interaction and networking. A Network File System (NFS) through the head node allowed the computational nodes to access and modify files available to all other nodes.
The finished five-node cluster, named Jaguar, had one head node for local user interface and four computational nodes, as shown in Figure 1.
Each node consists of one Pentium-S 200MHz processor, an FIC PT2006 motherboard, 64 megabytes of RAM, 2 gigabytes of local harddrive space, an S3 ViRGE video card, and a 3Com network interface card (NIC). Interconnecting the nodes is a Belkin 10/100 five-port Ethernet switch. Figure 2 shows the internal configuration of an individual node.
2.2 Software

Figure 2: The internal configuration of a single node of the Beowulf cluster, Jaguar. Each node had a FIC PT2006 motherboard, 64 megabytes of RAM, a 2 gigabyte harddrive, an S3 ViRGE video card, and a 3Com network interface card. Each node had a minimal hardware configuration so it could devote the maximum amount of system resources to running calculations.
Above the hardware layer is one of the most important system components in a cluster: the software environment. The central software package running on any computer is the operating system. In a Linux cluster, the choice of operating system determines which software packages will work on the system and how much effort will be required to make the software work correctly. Jaguar used an off-the-shelf version of RedHat Linux 7.2. During the install process, unnecessary software packages that normally accompany the operating system (e.g. OpenOffice) were removed. After completion, the system achieved improved run-times and tightened security through the removal of unnecessary services and processes (e.g. kudzu and Apache). For security, each node ran a Secure Shell (SSH) server program, and, for the ease of running parallel programs, each node was configured so that it could logon to any other node through SSH without a password. However, SSH access to the compute nodes from outside the cluster was restricted using the head node. The head node acted as the cluster router to the internet, and it contained a software firewall and used Network Address Translation (NAT) to disguise outgoing traffic and block unwanted incoming traffic. All incoming traffic, except that through SSH, was rejected by the head node.
The head node also had a second hard drive configured as a Network File System (NFS) drive for the other nodes; this hard drive contained all the user files and software applications. Among the software packages installed on all machines were the Portland Group Workstation version 5.1, MPICH version 1.2.5, LAM-MPI version 6.5.9, and OpenPBS. The Portland Group Workstation includes compilers for FORTRAN 90, the programming language used in the majority of the test programs; OpenPBS is a queue system that controls the input to the MPI implementations. To simplify the testing process, OpenPBS was not used. Additionally, LAM-MPI uses a different method of running programs than MPICH; with LAM-MPI, each node required access to the LAM-MPI binaries before a parallel program can run. Initially, the head node had the main copy of the LAM-MPI package, and all others had access to it through the shared drive. However, due to difficulties running a newly compiled version of LAM-MPI over a NFS drive, the nodes instead ran the pre-compiled version of the MPI implementation.
2.3 Program Design
To better compare the parallel-software packages, the design and testing of parallel programs involved two categories: example and practical. The example programs were MPI based parallel algorithms that did not serve any purpose with their message passing. Rather, the parallel method calls were implemented for timing and testing purposes. The practical programs were solutions to real and exemplary mathematical and computer science problems. After the initial versions of the programs were complete, the programs were combined with scripts to repeat each parallel algorithm ten times and write the individual timing results to files.
The first of the example programs only tested the implicit MPI timing mechanism. The timing function is a primary focus of the experiment because a significant difference in package implementation of the timing call could bias the data for the rest of the experiment. This program was an extremely simple parallel program; it recorded the exact time at successive calls to the function MPI_Wtime. The resulting difference in time between the calls is the minimum additional time added to the recorded time for any other call. Since latency of data transfers increases with the number of processes and processors used, the results include tests of the programs with a varied number of processors. Even though no mathematical computations are in the call, the latency for this call alone could increase with the number of processors. Data from the timing program included run-times on one, three, and five processors.
The second of the example programs utilized the timing methods tested in the first example program, although it tested the amount of time required to make other MPI calls. This program made timed calls to nine different MPI based functions, not including MPI_Wtime and the initialization calls. The results have data for MPI_BCAST (broadcast the same data to many processes), MPI_SCATTER (parse and send unique data to individual processes), MPI_REDUCE (receive data from many processors and perform a mathematical transform on the data), MPI_SENDRECV (concurrently send and receive data), MPI_SEND (send data to only one process), and MPI_RECV (receive data from only one process). This example program also made specific calls using varied amounts of data; the sections with MPI_BCAST, MPI_SCATTER, MPI_SEND, and MPI_RECV all have calls using both large data sets and small data sets. The differences in results from varied data amounts comparatively remained the same despite modification in problem size, so only results from the largest data sets are presented. The results are based on a variable numbers of processors (one through five) and a fixed sized data set (one thousand elements in a standard FORTRAN integer array).
The first practical program was based on a parallel version of a matrix multiplier. The serial version of the program calculates the resulting matrix from the multiplication of two appropriately sized matrices using a standard matrix multiplication algorithm. The parallel version of the program sends out portions of the matrix using the MPI_SCATTER command, then it receives and sums the smaller matrices using MPI_REDUCE. Since the programs only used test data, the parallel versions did not require extraneous error checking methods for the data. With the parallel matrices program running on five processors, the wrapper script recorded timing information on calls to MPI_REDUCE and MPI_SCATTER with different sized vectors and matrices.
The second practical program approximates the value of pi using integral calculus. The algorithm approximates the integral equivalent of pi by calculating the area under a curve using the trapezoid method. The parallel version of the program assigns each processor a range of values for which it is to compute and sum the area of trapezoids under the curve. The main part of the program receives the completed areas from the other processes and sums these values using MPI_REDUCE. This program used a version of the mathematical algorithm implemented in a parallel fashion; it also included the timing and looping calls to record the time required the run the reducing function. The data presented from the computations of pi are based on the program running on five processors using successively more and smaller trapezoids.
3.0 Results

Figure 3: Time differences between MPI implementations when testing the timing function MPI_Wtime. The blue line shows the time required to run the function MPI_Wtime using the MPICH implementation using 1, 3, and 5 processors; the red line is the times required when using LAM-MPI. The function MPI_Wtime measures the "wall" time or clock time when called; if the function is called two in succession, the difference between recorded values represents the added latency to time any call. The call times were measured while running the cluster using one, three, and five nodes; no significant timing differences exist with increasing number of nodes. Although LAM-MPI does show slightly lower values, the difference is negligible when factored into other timing values.
The data sets from the completed trials for the two MPI based packages have statistical trends and attributes. Comparing the mean-values from each set most accurately exemplifies the different temporal trends within the data. Each graph displays the mean results from one or more of the tests administered as a comparison between the two MPI packages. Although each graph displays a slightly different element of the features of MPI, all sets of results show trends regarding the differences of LAM-MPI and MPICH. The graphs are coded such that the functions tested are differentiated by color and the packages tested are differentiated by point markers.
The data set for the comparative results from the MPI-based timing mechanism running on one, three, and five processors is perhaps the most significant, as it sets the basis for the subsequent comparative tests. If a significant difference (as compared to times for other functions) did exist between the two implementations for the data on the timing function, then all later results and graphs would have to be adjusted to account for the offset in timing. The difference in timing (Figure 3) is noticeable between MPICH and LAM-MPI, but these results are insignificant when factored into the other tests. The differences in the timing function between implementations are on the level of microseconds, whereas the differences in parallel function calls are on the level of milliseconds. This thousand-fold difference in time scales is high enough to disregard any possible effect the timing function may have on further calculations.
The second program transfers randomly generated data between nodes but does not run any calculations using the transferred data. The program solely measures the time required to run these messaging calls and transfer the data. The results from this program are broken into two categories: global communication (Figure 4) and point-to-point communication (Figure 5).

Figure 4: Time differences between MPI implementations for "global" calls. The lines with solid markers indicate the tests run using MPICH, while the lines with empty markers were with LAM-MPI. The global communications calls broadcast (MPI_BCAST, blue lines), scatter (MPI_SCATTER, red lines), and reduce (MPI_REDUCE, green lines) all effectively transmit data from in a multi-node fashion using a minimal number of calls. MPI_BCAST sends one piece of data from one node to all others; MPI_SCATTER breaks a data into small pieces and sends a unique piece to each node; and MPI_REDUCE allows one node to receive data from all other nodes and perform a given operation on the data. MPICH and LAM-MPI have some relative differences in execution time for varying number of processors, although MPI_REDUCE for LAM-MPI does stand out when compared to the same function for MPICH.

Figure 5: Time to communication completion in MPI implementations for selected, non-global communications methods. The lines with solid markers indicate the tests run using MPICH, while the lines with empty markers were run with LAM-MPI. The point-to-point communications methods send, receive (MPI_SEND and MPI_RECV, red lines), and combined send/receive (MPI_SENDRECV, blue lines) are used to more efficiently transmit data between nodes; these methods are used when the data only needs to be transferred between two nodes. MPI_SEND sends data from one node to another; the receiving node executes MPI_RECV to prepare to receive the data; MPI_SENDRECV can be used to concurrently send and receive data. MPI_SENDRECV, when used properly, can speed communications; the timing differences between MPICH and LAM-MPI for calls to MPI_SENDRECV is of note.
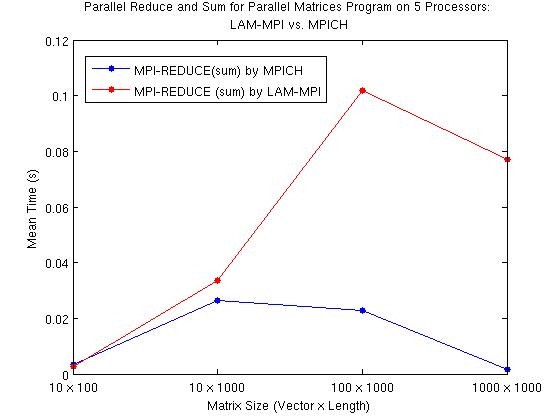
Figure 6 and Figure 7 (single caption for two figures): Comparative times to parallel program completion for computing resultant vector by matrix multiplication using different MPI implementations. The red lines are data taken when using LAM-MPI and the blue lines are from using MPICH. The comparative computational times with increasing data sets can be seen in the differences of the two curves with increasing data sets. This parallel program calculates the resultant matrix from a vector by matrix multiplication; the program recorded times for calls made to the functions MPI_SCATTER (Figure 3.3) and MPI_REDUCE (Figure 3.4) using five nodes. MPI_SCATTER breaks up the data and sends out chunks to individual nodes. For MPI_SCATTER, the two implementations show no significant differences on varying datasets. In reduction and sum with MPI_REDUCE, the two implementations show noticeable differences, especially as the size of the dataset increases.

Figure 7
The timing data from the parallel matrices program are from calls to MPI_SCATTER (Figure 6) and MPI_REDUCE (Figure 7) when running on five processors. The data taken from the MPI_SCATTER and MPI_REDUCE commands have curves that show the measured time to run these particular messaging functions using increasingly large data sets. For comparison, the timing data from the program that computes the value of pi are from calls made to the messaging function MPI_REDUCE with increasing complexity in the calculation (Figure 8).
4.0 Discussion and Conclusion

Figure 8: Comparative times for calls to MPI_REDUCE(sum) when used to compute the value of pi using an integral. The figure shows the slight differences in time when running MPI_REDUCE with increasingly large data sets. Parallel versions of numerical computations can quickly and efficiently solve a complex mathematical equation to many degrees of accuracy. The calculation of an integral based on the trapezoid rule, which uses functional values and an interpolating function to calculate the area under a curve, is an ideal example for a parallel program. The parallel program assigns each node a range of values to compute for the integral, and the sum of values from each node represents the total area under the curve. The small amount of data being sent between nodes probably accounts for the discrepancy between the times for MPI_REDUCE in this figure and those in Figure 3.4.
Although the results in Figure 3 exhibit a slight increase in call times as the number of processors goes up, the more significant trend is the slight difference in average time between calls. LAM-MPI has a slightly lower time, which could account for a very slight difference in measured call times for LAM-MPI based methods. However, even though the calls for the LAM-MPI version of MPI_Wtime are nearly twice as fast as the MPICH based version, the difference is insignificant (3 microseconds) relative to the total time cost of the other calls and may be disregarded in this context.
Figure 4, with data from the broadcast and scatter function, exemplifies how LAM-MPI has a faster algorithm than MPICH for certain calls. However, the difference in call times between the LAM-MPI and MPICH versions of the MPI_REDUCE algorithm is startling. On a larger data set, LAM-MPI takes a significantly longer time to compute an MPI_REDUCE based sum than MPICH does. In fact, of all the functions displayed on this graph, the trends for MPI_REDUCE are the most extreme. MPI_REDUCE is a versatile and common call in parallel programs. The difference in timing between implementations may be large enough to noticeably change the overall run-time on a lengthy program. Figure 7 again exemplifies the substantial difference in time between calls for MPICH and LAM-MPI for the MPI_REDUCE function; LAM-MPI appears to require more time to reduce a sum than MPICH.
Figure 5 displays the results for asynchronous MPI_SEND and MPI_RECV based point-to-point communication; LAM-MPI appears to be slightly more efficient, especially with increasing numbers of processors. The practical difference in processing time for small to medium data sets using these parallel methods is probably not noticeable, despite certain statistical differences, unless running computations whose times are measured in hours or days. When the times from concurrent data transfer through MPI_SENDRECV methods are compared, LAM-MPI and MPICH show a reverse trend. The times for point-to-point communication in LAM-MPI are relatively low at all number of nodes, while the times for the same function in MPICH are over five-fold above those of LAM-MPI. MPI_SENDRECV is a more commonly used point-to-point communications call in parallel programming, as it allows faster and simpler programs despite some avoidable pitfalls.
From the data based on the practical programs, the results initially do not show significant variation. Figure 6 displays the similarities in run-times for the two MPI implementations. However, Figure 7 displays a maximum of a four-fold difference in timing, which in computing can have a significant impact. In running these programs on ten-fold and hundred-fold iterations, a significant difference arises in run times. Since matrices greater than 1000 by 1000 in size are not uncommon in computing, the difference could be significant in some computations.
For parallel computation of pi, the data on the graph in Figure 8 contradicts the previously shown data on how the MPICH and LAM-MPI versions of MPI_REDUCE function relative to each other. However, the difference in times probably comes from the structure of the parallel algorithms. In computing the final sum for pi, the program only sends a small data set using MPI. The data being transferred through MPI are only the individual sums from each process; thus the nodes themselves do the majority of the computational work. In transferring the data, the call to MPI_REDUCE in the parallel pi calculation is at worst ten-fold as fast as the same call in the parallel matrices program. The parallel matrices program has to transfer much more data to fully compute the resultant matrix. Thus the LAM-MPI version of reduce is not as inefficient as it may initially appear. By design or accident, LAM-MPI is more efficient than MPICH with small data sets, while MPICH is more efficient with large data sets.
The data taken from successive and repeated tests of different parallel programs has some clear trends. LAM-MPI is more efficient and faster in many of the tested message passing calls, while MPICH is significantly more efficient in MPI_REDUCE. However, as this project examined only a handful of all the commonly used calls under strictly controlled programming circumstances, a more extensive assessment based on specific programming needs is necessary before switching libraries. Larger and smaller data sets should also be considered, as should the multitude of different MPI and MPI-2 based methods. Also, all test programs used FORTRAN90 as the programming language and the Portland Group FORTRAN compilers, while the two MPI packages may behave in a completely different fashion in a C or C++ programming environment. Though LAM-MPI does appear to have some more efficient algorithms than MPICH, these results can not necessarily be interpolated across different programming languages, compilers, operating systems, and hardware.
LAM-MPI also differs from MPICH in one important organizational aspect: whereas MPICH only requires SSH running on a node to start a parallel program, LAM-MPI needs an additional daemon running on the host to compile and run programs, and any hosts that run a portion of a parallel program must also have a special daemon running. The daemons could provide the means for a security breach on more public cluster. However, in a private environment, the ports opened by the daemon do not matter - i.e. if an intruder can reach the internal hosts then the head node has already been breached. From a programmer's viewpoint, these may not be important considerations; however, for a cluster administrator, security and organization are very important aspects to consider in choosing a parallel programming platform.
Some problems arose when programming with LAM-MPI's built-in run and compile commands, though the source of these errors were difficult to locate. Because of these problems, the project used the pre-compiled LAM-MPI package (specific to the cluster's hardware platform) rather than locally compiled source code. Although compiling MPICH versus using a pre-compiled version of LAM-MPI may have made a difference in method timing, the results do not show discrepancies that would arise from such a scenario. Additionally, most of the problems encountered with LAM-MPI were not in the MPI function calls but were instead in the wrapper scripts' interactions with the compilers. The combination of scripts and binary code made some aspects of debugging and programming easier and some more difficult, but did not appear to introduce a systematic bias or error into the results. However, the homogeneity of the cluster (using a single hardware and software architecture) could have given risen to some systematic error. To rule out such a bias, further experiments should compare more of the available parallel programming packages (such as PVM and MVICH) on a variety of the common hardware and software architectures.
This experiment elucidated the relative benefits and drawbacks between MPICH and LAM-MPI. Both implementations have certain general and specific advantages and weaknesses that arise in programming and in debugging. LAM-MPI has faster run-times for parallel communications, but MPICH had advantages under specific situations, such as when using large data sets. From these results, package selection should be based on specific programming or algorithmic needs and programmer experience. Because of programmer preference, MPICH will be the primary parallel communications package for code development on Jaguar. However, LAM-MPI will remain on the cluster for those that want to optimize their code or experiment with other libraries.
Acknowledgements
I would like to thank my undergraduate research advisor, Dr. J. David Hobbs, for continually encouraging my research. I also owe a debt of gratitude to Jennifer Parham, to whom I submitted this research, for running a parallel programming class over the AccessGrid. Funding for the project came from an NSF EPSCoR/Montana Tech Undergraduate Research Proposal.
References
Benson, G.D., Chu, C.W., Huang, Q., Caglar, S.G. (2003) A Comparison of MPICH Allgather Algorithms on Switched Networks. Lecture Notes in Computer Science 2840: 335 343.
Farrell, P.A. and Ong, H. (2003) Factors involved in the performance of computations on Beowulf clusters. Electronic Transactions on Numerical Analysis 15: 211-224.
Foster, I., Geisler, J., Kesselman, C., Tuecke, S. (1997) Managing Multiple Communication Methods in High-Performance Networked Computing Systems. Journal of Parallel and Distributed Computing 40: 35-48.
Ong, H. and Farrell, P. (2000) Performance Comparisons of LAM/MPI, MPICH, and MVICH on a Linux Cluster connected by a Gigabit Ethernet Network. Proceedings of the 4th Annual Linux Showcase and Conference 353-362.
Protopopov, B.V. and Skjellum, A. (2001) A Multithreaded Message Passing Interface (MPI) Architecture: Performance and Program Issues. Journal of Parallel and Distributed Computing 61: 449-466.
Squyres, J.M. and Lumsdaine, A. (2003) A Component Architecture for LAM/MPI. Lecture Notes in Computer Science 2840: 379387.
Sterling, T.L. (2001) Beowulf Cluster Computing with Linux. MIT Press.
Swann, C.A. (2001) Software for parallel computing: the LAM implementation of MPI. Journal of Applied Econometrics 16: 185-194.
Thakur, R. and Gropp, W.D. (2003) Improving the Performance of Collective Operations in MPICH. Lecture Notes in Computer Science 2840: 257-267.
Van Voorst, B. and Seidel, S. (2000) Comparison of MPI Implementations on a Shared Memory Machine. Lecture Notes in Computer Science 1800: 847.